Acesso
Criação de conta
Para solicitar a criação de conta e mais informações sobre o acesso, envie um e-mail para ndf-ti@usp.br utilizando o seu e-mail institucional com os seguintes dados: nome completo; email alternativo de contato (pode ser pessoal); tipo de vínculo (professor, aluno de doutorado, mestrado, IC, etc); orientador (se for o caso) e período de permanência (se for o caso), motivo para uso do recurso, softwares que pretende utilizar, se faz parte do projeto STMI e, se for não for membro do NDF, descrição de como soube dos recursos.
SSH Client
O acesso ao Mintrop se dá através de uma conexão SSH. Os sistemas operacionais Windows, Linux e macOS já possuem um cliente ssh instalado por padrão.
Caso o cliente ssh ainda não esteja ativado no seu Windows, siga os passos listados abaixo:
- Pressione WIN + I para abrir Settings
- Abra Apps > Apps & features
- Clique em Optional features
- Clique +Add a feature
- Procure OpenSSH Client na lista
- Selecione e clique em Install
- Reinicie o computador
Acessando os diferentes tipos de nós
Nó de visualização
Para acessar o nó de visualização é necessário o uso do pacote vglconnect, segue abaixo um passo a passo da instalação no Ubuntu 18.04.
-
- Fazer download o pacote virtualgl_2.6.3_amd64.deb no site:
https://sourceforge.net/projects/virtualgl/files/2.6.4/
- Fazer download o pacote virtualgl_2.6.3_amd64.deb no site:
-
- Abra o terminal, navegue até o diretório que contém o arquivo baixado e instale o vglconnect.
sudo apt install ./virtualgl_2.6.3_amd64.deb-
- Se conecte utilizando o vglconnect.
vglconnect -bindir /usr/bin -s user@consultar_ip_no_manual-
- Exemplo de uso de aplicação gráfica.
vglconnect -bindir /usr/bin -s user@consultar_ip_no_manual
module load paraview/5.8
paraviewNó FPGA
-
- Faça login usando o ssh.
ssh –X user@consultar_ip_no_manual-
- Abra a IDE Quartus para programar as FPGAs.
quartusNós de processamento
-
- Faça login usando o ssh.
ssh user@consultar_ip_no_manual
# Utilize o nó de login apenas para compilar programas e transferir dados, o processamento é feito exclusivamente pelos nós da fila.
Consulte como usar na seção SLURM.Recomendação de ferramentas
Screen
Quando estamos trabalhando em tarefas de longa duração em máquinas remotas, alguns problemas podem ocorrer: queda na conexão de internet; desconexão da sessão ssh; travamentos, entre outros. Quando algum desses problemas ocorre, o nosso trabalho é perdido.
Para evitar esse tipo de situação, podemos usar a ferramenta Screen ou GNU Screen, que é um multiplexador de terminais. Ele serve para que possamos iniciar uma sessão do screen dentro do terminal convencional, e nela criamos terminais virtuais, que podem continuar rodando mesmo quando estamos deconectados. Podemos deixar algo rodando no terminal do cluster, desconectar e voltar algum tempo depois para retomar do mesmo ponto em que paramos.
screen - Comandos básicos
#Lista as sessões
screen -ls
#Cria uma nova sessão com o nome "minha-sessao"
screen -S "minha-sessao"
#Se vincula a uma sessão existente de nome "minha-sessao"
screen -x minha-sessao
Comandos dentro do screen
Ctrl+A -> c #Cria um novo terminal
Ctrl+A -> " #Lista todos os terminais da sessão
Ctrl+A -> 0 #Alterna para o terminal 0
Ctrl+A -> A #Renomeia o terminal
Ctrl+A -> S #Divide a tela horizontalmente em duas regiões
Ctrl+A -> | #Divide a tela verticalmente em duas regiões
Ctrl+A -> tab #Alterna o foco nas regiões
Ctrl+A -> X #Fecha a região em foco
Ctrl+A -> Q #Fecha todas as regiões menos a que tem o foco
Ctrl+A -> Ctrl+a #Alterna o terminal
Ctrl+A -> d #Desvincula o seu terminal da sessão
Vim
Trabalhando no ambiente de linha de comando do cluster, muitas vezes será necessário abrir arquivos para leitura e eventualmente para edições, dessa forma, se faz necessário ter o conhecimento de algum editor de textos no terminal. Abaixo eu apresento alguns comandos básicos do Vim, um dos editores mais populares do Linux.
Vim - Comandos básicos
vim arquivo.txt #Abre o arquivo.txt, caso não ele não exista, um novo será criado
Abrir e salvar arquivo
Esc
:w #Salva o arquivo
:q #Sai do editor
:wq! #Salva e sai do editor
Busca
Esc
/word #Procura a palavra word de cima para baixo
?word #Procura a palavra word de baixo para cima
/jo[ha]n #Procura por john ou joan
/\< the #Procura por the, theatre ou then
Substituição
Esc
:%s/old/new/g #Substitui todas as ocorrências de old por new
:%s/old/new/gw #Substitui todas as ocorrências de old por new com confirmação
:2,35s/old/new/g #Substitui todas as ocorrências de old por new entre as linhas entre 2 e 35
:5,$s/old/new/g #Substitui todas as ocorrências de old por new da linhas 5 até o final do arquivo
:%s/^/hello/g #Insere hello no início de cada linha
Outros
Esc
:syntax on #Ativa o modo de exibição de cores de sintaxe
:set number #Exibe o número da linha
:set autoindent #Ativa o modo de identação automática
:set shiftwidth=4 #Configura o tamanho da identaçãoSSHFS
O SSHFS (Secure Shell FileSystem) é uma ferramenta que permite os usuários acessarem de forma segura um sistema de arquivos remoto, no exemplo a seguir, iremos acessar os diretórios da sua conta no Mintrop. Esse método é considerado seguro, pois a comunicação se dá através do protocolo SSH.
Uma vez estabelecida a conexão, é possível utilizar ferramentas da sua interface gráfica para manipular os arquivos.
-
- Instalando o SSHFS no seu computador:
sudo apt-get install sshfs-
- Criando o diretório que servirá para acessar os dados do Mintrop:
sudo mkdir ~/mintrop-fs-
- Estabelecendo a conexão:
# O Comando abaixo monta o HOME do Mintrop na máquina local
sudo sshfs -o allow_other user@consultar_ip_no_manual: ~/mintrop-fs-
- O diretório remoto deve aparecer no Natilus conforme a imagem abaixo:

-
- Desconectando do cluster:
sudo umount ~/mintrop-fsEntendendo as partições dos discos
Nós temos duas partições principais: /home e /scratch.
/home
O /home é a partição em que os diretórios $HOME de todos os usuários são armazenados, ex: /home/user.
Dentro de cada diretório $HOME, somente o usuário dono do mesmo é capaz de ler e escrever. Para que fosse possível o compartilhamento de programas e dados, instalados localmente, foi criado um diretório público, o /home/public. Utilize esse diretório caso queira instalar programas para o seu grupo de pesquisas.
Essa partição conta com 50TB e atualmente não tem cota de uso, apesar disso, a ocupação do disco é monitorada e, caso atinja um nível alto, será ativado algum tipo de restrição. Para evitar essa imposição do limite de uso, por favor, faça cópias dos seus dados e os apague do cluster.
/scratch
O /scratch é o local em que os usuários devem copiar os dados que serão utilizados na submissão de jobs, sejam eles scripts, datasets e etc. Os arquivos de saída também devem ser configurados para escrever nessa partição.
Segue abaixo um exemplo de como deve ser inserido no seu arquivo slurm:
export RUN_SCRATCH_DIR=/scratch/global/tmp-$SLURM_JOBID
mkdir $RUN_SCRATCH_DIR
rsync -av arquivos $RUN_SCRATCH_DIR
# Após a execução do job
rsync -av $RUN_SCRATCH_DIR/arquivos_de_saida ~/diretorio_do_home
Comparação de desempenho das partições:
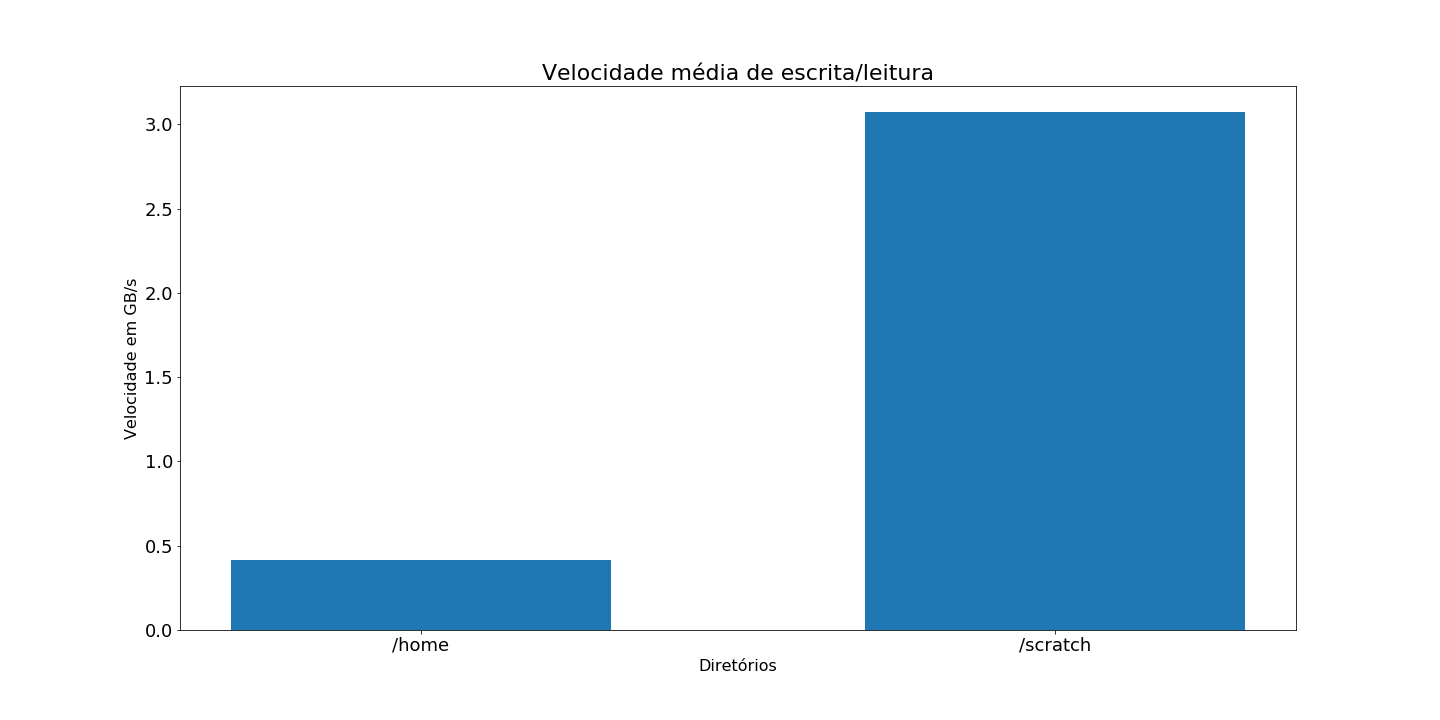
Isso ocorre porque o sistema de arquivos da partição scratch está otimizado para o uso em paralelo nos nós de processamento.
Transferência de dados
Como possuímos uma conta com permissão de conexão ssh, podemos transferir dados para o Mintrop ou do Mintrop para a nossa máquina, utilizando o scp, rsync, entre outros.
Abaixo há exemplos utilizando o rsync, troque os valores como usuário e nome de diretórios para os seus dados.
Enviando arquivos
Para enviar arquivos ou diretórios para o Mintrop, utilize o exemplo abaixo:
# rsync options source destination
rsync -av my_local_file_or_dir user@consultar_ip_no_manual:~/my_destination_dir/Recebendo arquivos
Para receber arquivos ou diretórios do Mintrop, utilize o exemplo abaixo:
# rsync options source destination
rsync -av user@consultar_ip_no_manual:~//my_remote_file_or_dir /home/user/my_local_destinationCaso você tenha utilizado o rsync para enviar seus dados para um servidor com IP público, o download tanto na sua máquina local quanto no Mintrop pode ser feito utilizando o wget. Exemplo:
wget http://my_ip/files/my_remote_fileRClone
Uma outra opção que pode ser utilizada por aqueles que possuem uma conta @usp ou acesso ao google drive ilimitado é o uso do rclone. Através desse programa é possível sincronizar o seu google drive e utilizá-lo para fazer cópias dos seus arquivos diretamente do terminal do Mintrop.
Abaixo eu mostro um passo a passo de como instalar e configurar o Rclone + Google Drive.
Instalação
-
- Faça login no Mintrop e Instale o rclone copiando e colando os comandos abaixo no seu terminal:
cd
wget https://downloads.rclone.org/rclone-current-linux-amd64.zip
unzip rclone-current-linux-amd64.zip
mv rclone-*-linux-amd64 rclone
cp ~/.bashrc ~/.bashrc_bkp
echo "alias rclone=~/rclone/rclone" >> ~/.bashrc
source ~/.bashrc-
- Configurando o rclone:
rclone config
No remotes found - make a new one
n) New remote
s) Set configuration password
q) Quit config
n/s/q> n
name> gdrive
Storage> drive
Google Application Client Id
Setting your own is recommended.
See https://rclone.org/drive/#making-your-own-client-id for how to create your own.
If you leave this blank, it will use an internal key which is low performance.
Enter a string value. Press Enter for the default ("").
client_id>
Google Application Client Secret
Setting your own is recommended.
Enter a string value. Press Enter for the default ("").
client_secret>
scope> 1
Enter a string value. Press Enter for the default ("").
root_folder_id>
Service Account Credentials JSON file path
Leave blank normally.
Needed only if you want use SA instead of interactive login.
Enter a string value. Press Enter for the default ("").
service_account_file>
Edit advanced config? (y/n)
y) Yes
n) No (default)
y/n> n
Remote config
Use auto config?
* Say Y if not sure
* Say N if you are working on a remote or headless machine
y) Yes (default)
n) No
y/n> y-
- Não feche a janela atual, abra um novo terminal no seu computador e digite:
ssh -L 53682:localhost:53682 user@consultar_ip_no_manual-
- Volte para a janela anterior, copie a url e cole no seu browser. Autorize a conta utilizando o seu e-mail @usp.br. Feche o browser e a janela com o túnel “ssh -L”.
-
- Volte para a janela do rclone para terminar a configuração:
Configure this as a team drive?
y) Yes
n) No (default)
y/n> n
y) Yes this is OK (default)
e) Edit this remote
d) Delete this remote
y/e/d> y
Current remotes:
Name Type
==== ====
gdrive drive
e) Edit existing remote
n) New remote
d) Delete remote
r) Rename remote
c) Copy remote
s) Set configuration password
q) Quit config
e/n/d/r/c/s/q> qComandos básicos do rclone
[user@headnode ~]$ rclone listremotes
gdrive:
[user@headnode ~]$ rclone mkdir gdrive:mintrop
[user@headnode ~]$ rclone lsd gdrive:
-1 2020-03-31 10:56:53 -1 Colab Notebooks
-1 2020-05-18 11:34:38 -1 Contas
-1 2020-06-23 12:24:46 -1 Matlab
-1 2020-06-23 18:31:02 -1 Meet Recordings
-1 2020-05-04 08:19:52 -1 Notas Reuniões RCGI
-1 2020-05-26 09:14:28 -1 RCGI - Documentos
-1 2020-06-24 14:44:02 -1 Software - SDumont
-1 2020-06-29 15:51:32 -1 mintrop
[user@headnode ~]$ rclone copy --progress ~/devito gdrive:mintrop/
Transferred: 522.467k / 170.668 MBytes, 0%, 7.957 kBytes/s, ETA 6h4m57s
Transferred: 83 / 464, 18%
Elapsed time: 1m5.6s
Transferring:
* docs/source/conf.py: 0% /11.753k, 0/s, -
* docs/source/builtins.rst: 0% /321, 0/s, -
* docs/source/constant.rst: 0% /102, 0/s, -
* devito/finite_differences/tools.py:100% /8.880k, 8.874k/s, 0s^C
[user@headnode ~]$ rclone delete gdrive:mintropModule
Um cluster HPC é compartilhado por muitos usuários, cada um deles com requerimentos de softwares diferentes. Por essa razão, a quantidade de aplicativos, bibliotecas e compiladores é muito grande e cada um desses pode ter diversas versões instaladas. Para facilitar a manutenção e evitar incidentes de segurança, essas aplicações são instaladas em locais não padrão.
Não é possível, ou ao menos não desejável, utilizar todos os softwares e bibliotecas ao mesmo tempo, versões diferentes da mesma aplicação costumam dar conflito.
Uma aplicação que vai para a produção deve ter o seu ambiente de bibliotecas e executáveis configurados, fora a aplicação em si. Isso é feito usando um conjunto de instruções e variáveis de ambiente para a aplicação em específico. Para simplificar esse procedimento, no Mintrop nós fazemos isso através da aplicação module.
Comandos básicos
Antes de começar com a compilação, é recomendado limpar todos os módulos carregados. Dessa forma, você terá maior controle dos módulos que estão em uso e ficará mais fácil de criar o script de submissão do job, como veremos na seção do SLURM.
module purge # Descarrega todos os módulos
module list # Lista os módulos carregados
module avail # Lista os módulos disponíveis
# É possível usar o avail com o nome parcial do módulo conforme exemplo:
[user@headnode ~]$ module avail open
----------- /opt/spack/share/spack/modules/linux-centos7-x86_64 -----------------
openblas-0.3.7-gcc-8.3.0-ex5qeai openmpi-3.1.5-gcc-8.3.0-557nw3c
openblas-0.3.7-gcc-8.3.0-n7wgnb4 openmpi-3.1.5-gcc-8.3.0-z3nft5q
openblas-0.3.9-gcc-4.8.5-rgk5tvj openmpi-3.1.5-intel-20.0.166-azljgh2
openblas-0.3.9-gcc-5.4.0-oaognw2 openmpi-3.1.6-gcc-4.8.5-auupnkt
openblas-0.3.9-gcc-8.3.0-e3xr7kn openmpi-3.1.6-gcc-5.4.0-tdlkv64
openfast-develop-gcc-5.4.0-3g2l4md openmpi-3.1.6-gcc-8.3.0-n2h2i7h
module load # Carregando um módulo
Exemplo: module load openmpi-3.1.5-gcc-8.3.0-z3nft5q
module unload # Descarregando um módulo
Exemplo: module unload openmpi-3.1.5-gcc-8.3.0-z3nft5q
module show # Mostra detalhes de um pacote que é passado por argumento
[user@headnode ~]$ module show openmpi-3.1.5-gcc-8.3.0-z3nft5q
--------------------------------------------------------------------------------------------------------------
/opt/spack/share/spack/modules/linux-centos7-x86_64/openmpi-3.1.5-gcc-8.3.0-z3nft5q:
--------------------------------------------------------------------------------------------------------------
whatis("An open source Message Passing Interface implementation. ")
prepend_path("PATH","/opt/spack/opt/spack/linux-centos7-x86_64/gcc-8.3.0/openmpi-3.1.5/bin")
prepend_path("MANPATH","/opt/spack/opt/spack/linux-centos7-x86_64/gcc-8.3.0/openmpi-3.1.5/share/man")
prepend_path("LD_LIBRARY_PATH","/opt/spack/opt/spack/linux-centos7-x86_64/gcc-8.3.0/openmpi-3.1.5/lib")
prepend_path("LIBRARY_PATH","/opt/spack/opt/spack/linux-centos7-x86_64/gcc-8.3.0/openmpi-3.1.5/lib")
prepend_path("CPATH","/opt/spack/opt/spack/linux-centos7-x86_64/gcc-8.3.0/openmpi-3.1.5/include")
prepend_path("PKG_CONFIG_PATH","/opt/spack/opt/spack/linux-centos7-x86_64/gcc-8.3.0/openmpi-3.1.5/lib/pkgconfig")
prepend_path("CMAKE_PREFIX_PATH","/opt/spack/opt/spack/linux-centos7-x86_64/gcc-8.3.0 openmpi-3.1.5/")
help([[An open source Message Passing Interface implementation. The Open MPI
Project is an open source Message Passing Interface implementation that
is developed and maintained by a consortium of academic, research, and
industry partners. Open MPI is therefore able to combine the expertise,
technologies, and resources from all across the High Performance
Computing community in order to build the best MPI library available.
Open MPI offers advantages for system and software vendors, application
developers and computer science researchers.
]])
Essas informações são úteis para resolver erros na hora da compilação.Compilando código no headnode
Abaixo, iremos compilar códigos C, mas o mesmo procedimento poderá ser utilizado para compilar um código de outra linguagem, desde que ele seja compatível com os compiladores disponíveis no cluster.
Compilando código C
Descarregando os módulos
[user@headnode webinar]$ module purge
Verificando a versão do GCC padrão do sistema
[user@headnode webinar]$ gcc --version
gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-39)
Copyright (C) 2015 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
A versão padrão do GCC não serve para o código do exemplo, por essa razão, vamos procurar todas as versões disponíveis do compilador.
[user@headnode webinar]$ module avail gnu
------------------ /opt/ohpc/pub/modulefiles ----------------------
gnu7/7.3.0 gnu8/8.3.0
Carregando a versão 8.3
[user@headnode webinar]$ module load gnu8/8.3.0
Verificando a versão carregada
[user@headnode webinar]$ gcc --version
gcc (GCC) 8.3.0
Copyright (C) 2018 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
Compilando o código
[user@headnode C_seq]$ gcc mandelbrot_seq.c -o mandelbrot_seqCompilando código C++ com openMP e openMPI
Descarregando os módulos
[user@headnode C_par]$ module purge
Para compilar esse código é necessário carregar as bibliotecas MPI, vamos usar o mpicc.
[user@headnode C_par]$ module avail openmpi
---------------------- /opt/spack/share/spack/modules/linux-centos7-x86_64 ------------------------
openmpi-3.1.4-gcc-8.3.0-rwl3ev4 openmpi-3.1.5-intel-20.0.166-azljgh2 openmpi-3.1.6-gcc-8.3.0-n2h2i7h
openmpi-3.1.5-gcc-8.3.0-557nw3c openmpi-3.1.6-gcc-4.8.5-auupnkt
openmpi-3.1.5-gcc-8.3.0-z3nft5q openmpi-3.1.6-gcc-5.4.0-tdlkv64
Carregando a versão 3.1.5
[user@headnode C_par]$ module load openmpi-3.1.5-gcc-8.3.0-557nw3c
Compilando o código
[user@headnode C_par]$ mpicc -std=c11 mandelbrot_mpi_omp.c -o mandelbrot_mpi_omp -fopenmpSLURM
Comandos básicos
sinfo - Exibe informação sobre as filas do SLURM
[user@headnode ~]$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
gpu_debug up 30:00 2 alloc n[11-12]
amd_debug up 30:00 2 alloc n[13-14]
arm_debug up 30:00 1 idle n17
intel_interactive up 1-00:00:00 1 idle n10
gpu_small up 1-00:00:00 2 alloc n[11-12]
amd_small up 1-00:00:00 2 alloc n[13-14]
intel_small* up 1-00:00:00 9 alloc n[01-09]
arm_small up 1-00:00:00 1 idle n17
gpu_large up 3-00:00:00 2 alloc n[11-12]
amd_large up 3-00:00:00 2 alloc n[13-14]
intel_large up 3-00:00:00 9 alloc n[01-09]
arm_large up 3-00:00:00 1 idle n17
squeue - Exibe os jobs nas diferentes filas
O comando exibe todos os jobs na fila, use o -u user para listar apenas as suas submissões
squeue -u user
Para ter uma estimativa de quando o job iniciará utilize o --start
squeue --start -u user
scancel - Comando utilizado para cancelar jobs
Verifique o job_id com o squeue e depois use como argumento para o scancel
scancel job_id
srun - Aloca os recursos e roda a aplicação de imediato, é possível rodar no modo interativo e usar o shell
sbatch - Submete o trabalho para uma fila, aloca os recursos e roda de forma não interativasrun – Rodando um script em python em modo interativo
-
- Reserve um ou mais nodes para execução com o srun.
srun --mail-type=BEGIN --mail-user=user@usp.br --nodes=1 --cpus-per-task=40 -p intel_interactive --pty bash -i
# --mail-type=BEGIN envia um e-mail quando o job inicia
# --mail-user=mail@usp.br endereço para o qual a mensagem será enviada
# --nodes=N quantidade de nodes
# --ntasks-per-node= número de processos por nó (MPI)
# -p partição/fila que será utilizada, verifique a
disponibilidade e nomes com o sinfo
# --pty bash -i retorna uma sessão bash-
- Carregue o python e todas as dependências do seu código. Neste exemplo, utilizaremos um código de benchmark do devito.
Para facilitar o carregamento dos módulos, crie um arquivo com todos os pacotes necessários.
vim module_devito.sh
module purge
module load py-devito-4.2.1-gcc-8.3.0-4imtovj
module load gnu8/8.3
module load py-numpy-1.18.1-gcc-8.3.0-npn5loa
module load py-setuptools-41.4.0-gcc-8.3.0-73y6pbp
module load py-traitlets-4.3.3-gcc-8.3.0-2bzs6tu
module load py-defusedxml-0.5.0-gcc-8.3.0-kx2t6ed
module load py-testpath-0.4.2-gcc-8.3.0-i5wfoxe
module load py-pandocfilters-1.4.2-gcc-8.3.0-xvyyfnw
module load py-bleach-3.1.0-gcc-8.3.0-vogfgib
module load py-entrypoints-0.3-gcc-8.3.0-w64fsom
module load py-nbformat-4.4.0-gcc-8.3.0-jkatgmq
module load py-jinja2-2.10.3-gcc-8.3.0-lxh7yfs
module load py-mistune-0.8.4-gcc-8.3.0-pbgb6rx
module load py-markupsafe-1.1.1-gcc-8.3.0-tj73cyb
module load py-decorator-4.4.0-gcc-8.3.0-d4cmwzv
module load py-notebook-6.0.1-gcc-8.3.0-5mrqelm
module load py-prometheus-client-0.7.1-gcc-8.3.0-geq53ae
module load py-terminado-0.8.1-gcc-8.3.0-hsojx2y
module load py-send2trash-1.5.0-gcc-8.3.0-e4ds5lm
module load py-ipython-7.3.0-gcc-8.3.0-pmkqeyv
module load py-pexpect-4.6.0-gcc-8.3.0-lwpj2d6
module load py-ptyprocess-0.5.1-gcc-8.3.0-tiytcov
module load py-pickleshare-0.7.4-gcc-8.3.0-xchpyts
module load py-backcall-0.1.0-gcc-8.3.0-uu5tome
module load py-prompt-toolkit-2.0.9-gcc-8.3.0-cvwdfcq
module load py-wcwidth-0.1.7-gcc-8.3.0-53vzf6q
module load py-matplotlib-3.1.2-gcc-8.3.0-mdvfr45
module load py-pyparsing-2.4.2-gcc-8.3.0-me2hdnq
Carregue os módulos com o source
source module_devito.sh-
- Configure as variáveis de ambiente.
export DEVITO_ARCH=gcc
export DEVITO_PLATFORM=intel64
export DEVITO_LOGGING=DEBUG
export DEVITO_LANGUAGE=openmp
export DEVITO_AUTOTUNING=aggressive
export OMP_NUM_THREADS=40 # Esse valor está de acordo com o cpus-per-task-
- Execute o código.
[user@n10 ipython]$ export exec_devito=/opt/spack/opt/spack/linux-centos7-x86_64/gcc-8.3.0/py-devito-4.2.1-4imtovjchnmo6mibw6hk4bfgxvwfo3kk/lib/python3.6/site-packages/benchmarks/user/benchmark.py
python $exec_devito bench -P acoustic -d 512 512 512 -so 12 --arch gcc --tn 100 -a aggressivesrun – Acessando o jupyter notebook remotamente
-
- Crie o diretório kernels/python3 para configurar a entrada para o módulo python3. Esse passo só é necessário na primeira execução.
mkdir -p ~/.local/share/jupyter/kernels/python3/
vim ~/.local/share/jupyter/kernels/python3/kernel.json
{
"argv": [
"/opt/spack/opt/spack/linux-centos7-x86_64/gcc-8.3.0/python-3.6.8-pfdclbjq754cgr3oyjp5fel2ebqcwant/bin/python",
"-m",
"ipykernel_launcher",
"-f",
"{connection_file}"
],
"display_name": "Python 3",
"language": "python"
}-
- Crie um arquivo com os módulos necessários.
Para facilitar o carregamento dos módulos, crie um arquivo com todos os pacotes necessários.
vim module_jupyter_devito.sh
module purge
module load gnu8/8.3
module load py-devito-4.2.1-gcc-8.3.0-4imtovj
module load py-jupyter-core-4.6.0-gcc-8.3.0-7pch7j6
module load py-jupyter-client-5.3.4-gcc-8.3.0-xjxx52r
module load py-ipykernel-5.1.0-gcc-8.3.0-pnhvx73
module load py-nbconvert-5.6.0-gcc-8.3.0-cocw4d6
module load py-ipython-genutils-0.2.0-gcc-8.3.0-uf4o45w
module load py-setuptools-41.4.0-gcc-8.3.0-73y6pbp
module load py-traitlets-4.3.3-gcc-8.3.0-2bzs6tu
module load py-defusedxml-0.5.0-gcc-8.3.0-kx2t6ed
module load py-testpath-0.4.2-gcc-8.3.0-i5wfoxe
module load py-pandocfilters-1.4.2-gcc-8.3.0-xvyyfnw
module load py-bleach-3.1.0-gcc-8.3.0-vogfgib
module load py-entrypoints-0.3-gcc-8.3.0-w64fsom
module load py-nbformat-4.4.0-gcc-8.3.0-jkatgmq
module load py-jinja2-2.10.3-gcc-8.3.0-lxh7yfs
module load py-mistune-0.8.4-gcc-8.3.0-pbgb6rx
module load py-markupsafe-1.1.1-gcc-8.3.0-tj73cyb
module load py-decorator-4.4.0-gcc-8.3.0-d4cmwzv
module load py-notebook-6.0.1-gcc-8.3.0-5mrqelm
module load py-prometheus-client-0.7.1-gcc-8.3.0-geq53ae
module load py-terminado-0.8.1-gcc-8.3.0-hsojx2y
module load py-send2trash-1.5.0-gcc-8.3.0-e4ds5lm
module load py-ipython-7.3.0-gcc-8.3.0-pmkqeyv
module load py-pexpect-4.6.0-gcc-8.3.0-lwpj2d6
module load py-ptyprocess-0.5.1-gcc-8.3.0-tiytcov
module load py-pickleshare-0.7.4-gcc-8.3.0-xchpyts
module load py-backcall-0.1.0-gcc-8.3.0-uu5tome
module load py-prompt-toolkit-2.0.9-gcc-8.3.0-cvwdfcq
module load py-wcwidth-0.1.7-gcc-8.3.0-53vzf6q
module load py-matplotlib-3.1.2-gcc-8.3.0-mdvfr45-
- Use o srun para alocar um node e guarde o hostname.
srun --mail-type=BEGIN --mail-user=user@usp.br --nodes=1 --cpus-per-task=40 -p intel_interactive --pty bash -i
hostname-
- Configure as variáveis de ambiente.
Configurando o ambiente para o Devito
export DEVITO_ARCH=gcc
export DEVITO_PLATFORM=intel64
export DEVITO_LOGGING=DEBUG
export DEVITO_LANGUAGE=openmp
export DEVITO_AUTOTUNING=aggressive
export OMP_NUM_THREADS=40 # Esse valor está de acordo com o cpus-per-task-
- Rode o jupyter.
jupyter notebook --no-browser --ip=0.0.0.0-
- Crie um túnel para acessar o jupyter via browser da sua máquina local.
ssh -L 8888:hostname_node:8888 user@consultar_ip_no_manual
# Utilize o hostname do node alocado- Volte ao terminal com o output do jupyter notebook e abra o link no seu browser.
Exemplo com o firedrake
-
- Para criar uma entrada jupyter para o firedrake, crie o arquivo conforme o exemplo:
mkdir -p ~/.local/share/jupyter/kernels/firedrake
vim ~/.local/share/jupyter/kernels/firedrake/kernel.json
{
"argv": [
"/opt/ohpc/pub/apps/firedrake/20200204/gcc-8.3.0/bin/python3",
"-m",
"ipykernel_launcher",
"-f",
"{connection_file}"
],
"display_name": "Firedrake - Python 3",
"language": "python"
}-
- Crie o arquivo com os módulos necessários e o carregue com o source.
vim modulos_firedrake.sh
module purge
module load firedrake/20200204
module load py-jupyter-core-4.6.0-gcc-8.3.0-7pch7j6
module load py-jupyter-client-5.3.4-gcc-8.3.0-xjxx52r
module load py-ipykernel-5.1.0-gcc-8.3.0-pnhvx73
module load py-nbconvert-5.6.0-gcc-8.3.0-cocw4d6
module load py-ipython-genutils-0.2.0-gcc-8.3.0-uf4o45w
module load py-setuptools-41.4.0-gcc-8.3.0-73y6pbp
module load py-traitlets-4.3.3-gcc-8.3.0-2bzs6tu
module load py-defusedxml-0.5.0-gcc-8.3.0-kx2t6ed
module load py-testpath-0.4.2-gcc-8.3.0-i5wfoxe
module load py-pandocfilters-1.4.2-gcc-8.3.0-xvyyfnw
module load py-bleach-3.1.0-gcc-8.3.0-vogfgib
module load py-entrypoints-0.3-gcc-8.3.0-w64fsom
module load py-nbformat-4.4.0-gcc-8.3.0-jkatgmq
module load py-jinja2-2.10.3-gcc-8.3.0-lxh7yfs
module load py-mistune-0.8.4-gcc-8.3.0-pbgb6rx
module load py-markupsafe-1.1.1-gcc-8.3.0-tj73cyb
module load py-decorator-4.4.0-gcc-8.3.0-d4cmwzv
module load py-notebook-6.0.1-gcc-8.3.0-5mrqelm
module load py-prometheus-client-0.7.1-gcc-8.3.0-geq53ae
module load py-terminado-0.8.1-gcc-8.3.0-hsojx2y
module load py-send2trash-1.5.0-gcc-8.3.0-e4ds5lm
module load py-ipython-7.3.0-gcc-8.3.0-pmkqeyv
source activate firedrake-
- Rode o jupyter e crie o túnel em uma nova janela do terminal local.
jupyter notebook --no-browser --ip=0.0.0.0
ssh -L 8888:n10:8888 lmanrique@200.144.186.101sbatch – Submissão de jobs
O sbatch é utilizado para submeter jobs para a fila de execução, os arquivos submetidos aceitam a sintaxe do Shell Script, é possível criar arquivos, remover, configurar variáveis de ambiente, entre outros.
Além dos parâmetros do shell Linux, há parâmetros especiais do SLURM. Abaixo segue uma lista dos mais utilizados:
| Parâmetro | Função | Argumentos |
|---|---|---|
--nodes |
Número de nodes a ser alocado | Integer, de 1 até o limite da fila |
--cpus-per-task |
Número de cpus, utilizar para cofigurar o número de threads | Integer, de 1 até o limite de threads |
--nstaks |
Número de processos total, somando de todos os nodes alocados | Integer, de 1 até o máximo de cores alocados somados |
--nstasks-per-node |
Número de processos em cada node | Integer, de 1 até o número de cores do node |
--partition |
Seleciona a partição/fila a ser utilizada | Utilize os nomes de fila do sinfo |
--job-name |
Configura um nome para o job, ele aparecerá no squeue e output | Utilize qualquer string |
--output |
Gera um arquivo de saída para a execução do job | Exemplo: =R-%x.%j.out gera arquivo com nome do job e id |
--error |
Gera um arquivo de saída para os erros da execução do job | Exemplo: =R-%x.%j.err gera arquivo com nome do job e id |
--mail-type |
Especifica para quais ações deve-se disparar um e-mail | NONE, BEGIN, END, FAIL, REQUEUE, ALL |
--mail-user |
Configura o e-mail do destinatário | E-mail válido |
--exclusive |
Aloca o node para uso exclusivo | ———————————————— |
Exemplos SLURM
OpenFOAM
Para rodar o openFOAM em paralelo é necessário configurar os arquivos da execução, gerar Mesh e decompor o problema. Abaixo descrevo o passo a passo para rodar em 32 processos MPI. Para replicar o modelo, você deve alterar os diretórios para o seu diretório \$HOME.
-
- Preparando o ambiente com as variáveis e compiladores.
module purge
module load gnu8/8.3
module load openfoam-org-7.0-gcc-8.3.0-6h2mj4b
export FOAM_RUN=$HOME/run-
- Copiando os exemplos para o seu diretório $FOAM_RUN.
mkdir $HOME/run
cp -r /opt/spack/opt/spack/linux-centos7-x86_64/gcc-8.3.0/openfoam-org-7.0-6h2mj4be6fcizqimlg23mpgub65wtqkv/tutorials $FOAM_RUN-
- Modificando os arquivos para rodar em paralelo.
cd $FOAM_RUN/tutorials/multiphase/interFoam/laminar
mkdir damBreakFine
cp -r damBreak/damBreak/0 damBreakFine
cp -r damBreak/damBreak/system damBreakFine
cp -r damBreak/damBreak/constant damBreakFine-
- Altere o block do arquivo blockMeshDict.
cd damBreakFine/system
vim blockMeshDict # Remova as linhas do block e insira as linhas a seguir
blocks
(
hex (0 1 5 4 12 13 17 16) (46 10 1) simpleGrading (1 1 1)
hex (2 3 7 6 14 15 19 18) (40 10 1) simpleGrading (1 1 1)
hex (4 5 9 8 16 17 21 20) (46 76 1) simpleGrading (1 2 1)
hex (5 6 10 9 17 18 22 21) (4 76 1) simpleGrading (1 2 1)
hex (6 7 11 10 18 19 23 22) (40 76 1) simpleGrading (1 2 1)
);
cd ..
blockMesh-
- Copiando arquivos e configurando field values.
cp -r 0/alpha.water.orig 0/alpha.water
setFields-
- Configurando o subdomains para rodar em paralelo, configure para o número de processos que irá utilizar.
cd system
vim decomposeParDictaltere de:
numberOfSubdomains 4;
method simple;
coeffs
{
n (2 2 1);
}
distributed no;para:
numberOfSubdomains 32;
method simple;
coeffs
{
n (4 4 2);
}
distributed yes;Decompondo em regiões.
cd ..
decomposePar-
- Os arquivos estão prontos para rodar em paralelo, use o arquivo .slurm para submeter o job com o sbatch conforme o exemplo:
#!/bin/bash
#SBATCH --nodes=2 #Número de Nós
#SBATCH --ntasks-per-node=16 #Número total de processos
#SBATCH --ntasks=32 #Número de processos por node
#SBATCH -p intel_small #Fila (partition) a ser utilizada
#SBATCH -J openfoam #Nome job
#SBATCH --output=R-%x.%j.out
#SBATCH --error=R-%x.%j.err
#SBATCH --mail-user=user@usp.br #Configura o destinatário
#SBATCH --mail-type=BEGIN #Envia email ao iniciar o job
#SBATCH --exclusive
#Preparando o diretório scratch
export RUN_SCRATCH_DIR=/scratch/global/tmp-$SLURM_JOBID
mkdir $RUN_SCRATCH_DIR
#Criando o arquivo hosts
export HOSTFILE=$RUN_SCRATCH_DIR/host-$SLURM_JOBID
srun hostname > $HOSTFILE
#Limpa o cache de módulos
module purge
#Carregando os módulos
module load gnu8/8.3
module load openfoam-org-7.0-gcc-8.3.0-6h2mj4b
#Entrando no diretório do scratch
cd $RUN_SCRATCH_DIR
#Configurando a variável run do openFOAM
export FOAM_RUN=/home/lmanrique/webinar/slurm/openFOAM/run/
#Rodando o openFOAM em paralelo
mpirun -n $SLURM_NTASKS -npernode $SLURM_NTASKS_PER_NODE -machinefile $HOSTFILE interFoam -case $FOAM_RUN/tutorials/multiphase/interFoam/laminar/damBreakFine -parallel
#Copiando o resultado para o $HOME
rsync -av $RUN_SCRATCH_DIR/ results-$SLURM_JOBID/Devito
#!/bin/bash
#SBATCH --nodes=1 #Número de Nós
#SBATCH --cpus-per-task=32 #Número de threads
#SBATCH -p gpu_small #Fila (partition) a ser utilizada
#SBATCH -J devito-example #Nome job
#SBATCH --mail-user=user@usp.br #Configura o destinatário
#SBATCH --mail-type=BEGIN #Envia email ao iniciar o job
#SBATCH --output=R-%x.%j.out
#SBATCH --error=R-%x.%j.err
#SBATCH --exclusive
#Preparando o diretório scratch
export RUN_SCRATCH_DIR=/scratch/global/tmp-$SLURM_JOBID
mkdir $RUN_SCRATCH_DIR
#Limpa o cache de módulos
module purge
#Configurando os compiladores Intel
module load intel/2020.0.166
#Configurando o Devito e pacotes python
module load py-devito-4.2.1-intel-20.0.166-eiizm6q
module load py-matplotlib-3.1.2-gcc-8.3.0-mdvfr45
#Entrando no diretório scratch
cd $RUN_SCRATCH_DIR
#Configurando os parâmetros de otimização do Devito
export DEVITO_ARCH=icc
export DEVITO_PLATFORM=intel64
export DEVITO_LOGGING=DEBUG
export DEVITO_LANGUAGE=openmp
export DEVITO_AUTOTUNING=aggressive
export OMP_NUM_THREADS=$SLURM_CPUS_PER_TASK
#Rodando o benchmark do Devito
export EXEC_DEVITO=/opt/spack/opt/spack/linux-centos7-x86_64/gcc-8.3.0/py-devito-4.2.1-4imtovjchnmo6mibw6hk4bfgxvwfo3kk/lib/python3.6/site-packages/benchmarks/user/benchmark.py
python $EXEC_DEVITO bench -P acoustic -d 512 512 512 -so 12 --arch gcc --tn 100 -a aggressive
#Copiando os arquivos gerados para o diretório de submissão
rsync -av $RUN_SCRATCH_DIR/ $SLURM_SUBMIT_DIR/results-$SLURM_JOBIDFiredrake
#!/bin/bash
#SBATCH --nodes=1 #Número de Nós
#SBATCH --cpus-per-task=40 #Número de threads
#SBATCH -p intel_small #Fila (partition) a ser utilizada
#SBATCH -J firedrake-example #Nome job
#SBATCH --mail-user=user@usp.br #Configura o destinatário
#SBATCH --mail-type=BEGIN #Envia email ao iniciar o job
#SBATCH --output=R-%x.%j.out
#SBATCH --error=R-%x.%j.err
#SBATCH --exclusive
#Preparando o diretório scratch
export RUN_SCRATCH_DIR=/scratch/global/tmp-$SLURM_JOBID
mkdir $RUN_SCRATCH_DIR
#Limpa o cache de módulos
module purge
#Configurando os compiladores GNU e git
module load gnu8/8.3
module load git-2.25.0-gcc-8.3.0-garapnb
#Configurando o Firedrake
module load firedrake/20200204
source activate firedrake
#Copiando os arquivos para o scratch
rsync -av helmholtz.py $RUN_SCRATCH_DIR
#Entrando no scratch e rodando o script com exemplo do firedrake
cd $RUN_SCRATCH_DIR
python helmholtz.py
#Copiando os arquivos gerados para o diretório de submissão
rsync -av $RUN_SCRATCH_DIR/ $SLURM_SUBMIT_DIR/results-$SLURM_JOBIDCódigo genérico MPI
#!/bin/bash
#SBATCH --nodes=2 #Número de Nós
#SBATCH --ntasks-per-node=32 #Número total de processos
#SBATCH --ntasks=64 #Número de processos por node
#SBATCH -p gpu_large #Fila (partition) a ser utilizada
#SBATCH -J mandelbrot_mpi_omp #Nome job
#SBATCH --output=R-%x.%j.out
#SBATCH --error=R-%x.%j.err
#SBATCH --mail-user=user@usp.br #Configura o destinatário
#SBATCH --mail-type=BEGIN #Envia email ao iniciar o job
#SBATCH --exclusive
#Preparando o diretório scratch
export RUN_SCRATCH_DIR=/scratch/global/tmp-$SLURM_JOBID
mkdir $RUN_SCRATCH_DIR
#Criando o arquivo hosts
export HOSTFILE=$RUN_SCRATCH_DIR/host-$SLURM_JOBID
srun hostname > $HOSTFILE
#Limpa o cache de módulos
module purge
#Carregando os modulos
module load gnu8/8.3
module load openmpi-3.1.5-gcc-8.3.0-557nw3c
#Entrando no diretório do scratch
cd $RUN_SCRATCH_DIR
#Rodando o código com o mpirun
mpirun -n $SLURM_NTASKS -npernode $SLURM_NTASKS_PER_NODE -machinefile $HOSTFILE --display-map $SLURM_SUBMIT_DIR/mandelbrot_mpi_omp 2
#Copiando os arquivos gerados para o diretório de submissão
rsync -av $RUN_SCRATCH_DIR/ $SLURM_SUBMIT_DIR/results-$SLURM_JOBID